
Výchozí možnost hledání – modul Search
Modul pro jednoduchou implementaci vyhledávání je přítomen přímo v jádře systému Drupal (modul Search). Modul pracuje na principu fulltextové indexace, tj. vytváření indexu výrazů v databázi, na základě kterého lze pak obsah rychle prohledat a sestavit seznam URL adres, na kterých se hledaný výraz vyskytuje. Funkcionalita tohoto modulu je poměrně striktně daná, lze ovlivnit:
- minimální délku slova které se indexuje
- váhu faktorů jednotlivých indexovaných uzlů obsahu (stránek) – lze např. nastavit že novějšímu obsahu nebo více čtenému obsahu se bude přiřazovat při sestavování výsledků hledání větší váha
Další vlastnosti tohoto typu hledání jsou:
- lze použít buď jednoduchý formulář s polem pro hledaný text, nebo zobrazit pokročilejší hledání, které podporuje možnosti obsahuje kterékoliv slovo / obsahuje frázi / neobsahuje žádné ze slov, dále omezení na vybrané typy obsahu (např. článek, stránka, aktualita apod.) a na zvolený jazyk nebo všechny jazyky
- lze použít logické spojky AND a OR
- prohledává se pouze textový obsah uložený v databázi, tedy nikoliv např. PDF soubory apod.
- Vyhledávání nerozlišuje malá a velká písmena, ale rozlišuje znaky s diakritikou (vyhledávání slova „článek“ vrátí jiné výsledky než „clanek“)
- vyhledávání nepodporuje nijak ohýbání slov (stemming)
Tento základní modul je tedy vhodný skutečně pouze pro to nejjednodušší použití a nelze od něj očekávat žádné pokročilejší možnosti ohledně řízení způsobu prohledávání ani sestavování výsledků hledání.
Pokročilejší hledání – Search API
Pokud jsou nároky na vyhledávání na webu vyšší, je třeba sáhnout po jiném řešení. K dispozici jsou rozšiřující moduly kterými je možné v implementaci dosáhnout vyššího standardu pro fulltextové hledání, nejběžnější volbou je modul Search API a jeho doplňkové moduly.
Modul Search API je založen na principu univerzálního vyhledávacího modulu, který do značné míry abstrahuje od konkrétní vyhledávací (tj. indexovací a dotazovací) technologie a umožňuje na jedné straně nasadit zvolenou vyhledávací technologii a univerzálním způsobem ji řídit a konfigurovat, na straně druhé pak vytvářet vyhledávací stránky, na kterých lze definovat vyhledávací formuláře, způsob prohledávání a způsob prezentace výsledků hledání.
Co se týká vyhledávacích stránek, využívá se v tomto případě univerzální modul Views, který umožňuje definovat nejrůznější výpisy dat, vystavovat formuláře, definovat formátování výsledků apod.
Co se týká indexování obsahu a dotazování, musí se v rámci Search API vždy použít doplňkový modul, který pracuje s konkrétní vyhledávací technologií.
Výchozím dostupným modulem je Database Search, který v zásadě pracuje na podobném principu jako výchozí modul Drupalu Search, tedy pracuje výhradně s databází a v ní vytváří fulltextové indexy, ovšem jeho možnosti jsou v porovnání s výchozím Search výrazně bohatší.
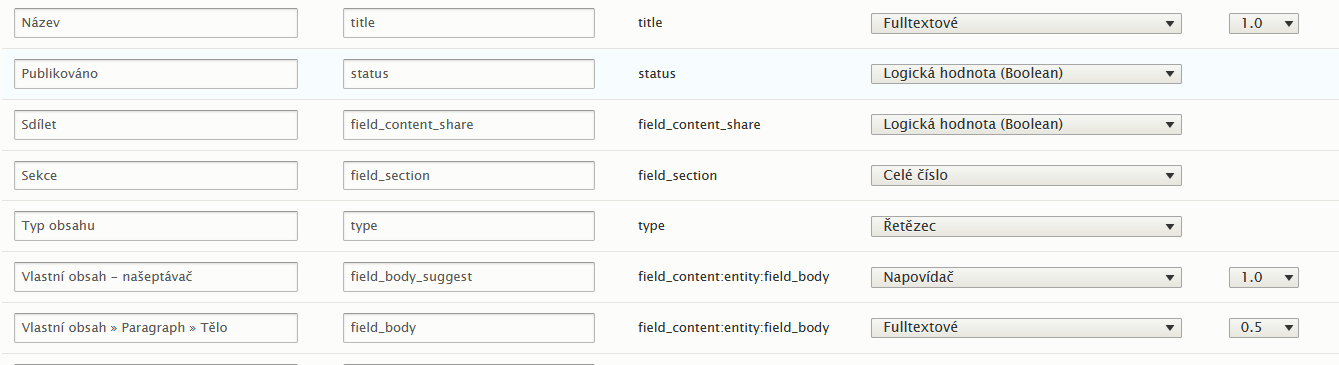
Pro fulltextový index, který se pomocí tohoto modulu vytváří, lze definovat:
- Jaké typy obsahu (nebo případně jiné entity Drupalu – např. taxonomie) se prohledávají
- Jaké jazyky se prohledávají
- Jaká pole se indexují a prohledávají a jakým způsobem (jsou např. volby prohledávat pole fulltextově, jako řetězec, jako logickou hodnotu apod.)
- Jaké procesory se při indexaci a prohledávání aplikují
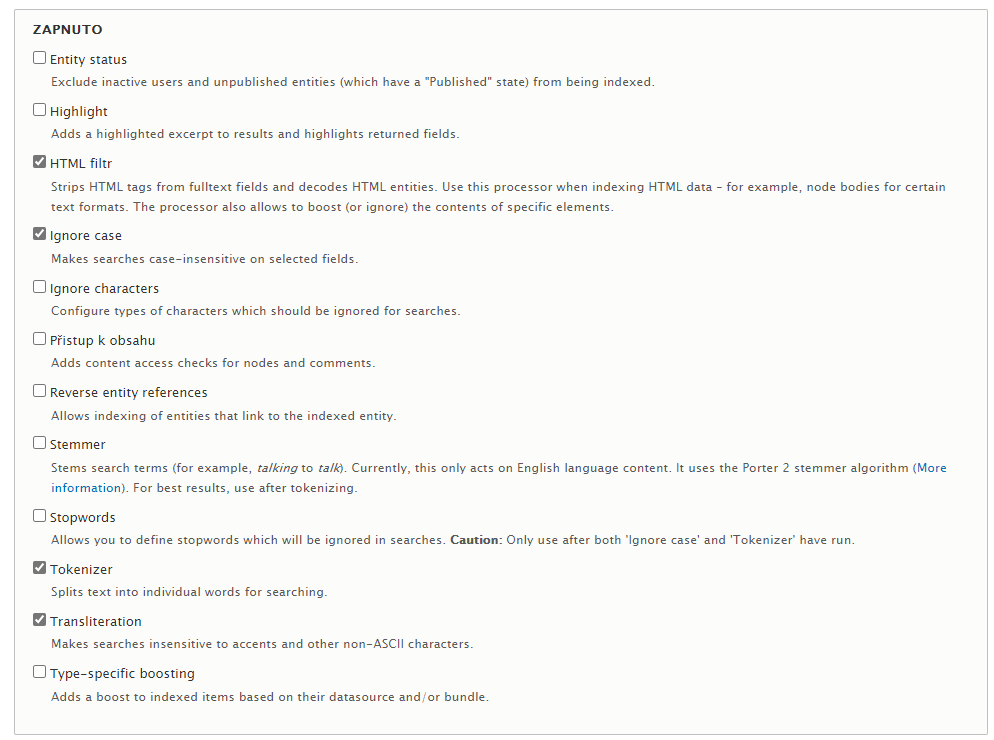
Pokročilé vlastnosti řešení jsou skryty zejména za těmito procesory, kterých je celá řada, mezi ty nejzajímavější patří zejména:
- Tokenizer – zajišťuje dělení indexovaného textu do slov, lze definovat oddělovače slov či výrazů, minimální délku indexovaného slova apod.
- HTML filtr – zajišťuje extrakci vlastního textu z HTML kódu, zajímavou možností je např. definovat váhu textu uvnitř jednotlivých HTML značek a tím vyznačit že např. nadpisy (H1, H2 apod.) mají z hlediska vyhledávání větší význam než běžné odstavce textu
- Nerozlišování malých / velkých písmen
- Transliteration, neboli práce s diakritikou (pokud je zapnuto, tak např. „č“ se z hlediska hledání považuje za stejný znak jako „c“)
- Ignorované znaky – lze specifikovat které znaky (formou výběru nebo regulárních výrazů) jsou při indexaci kompletně ignorovány
- Stopwords – lze definovat slovník slov, které se neindexují – typicky např. spojky, přeložky apod.
- Stemmer – extrakce slovních základů umožňující hledat různé tvary stejného slova; modul Database Search však v tomto případě podporuje pouze slovník pro angličtinu, takže tato volba je v českém prostředí využitelná pouze pro weby vytvářené v anglickém jazyce.
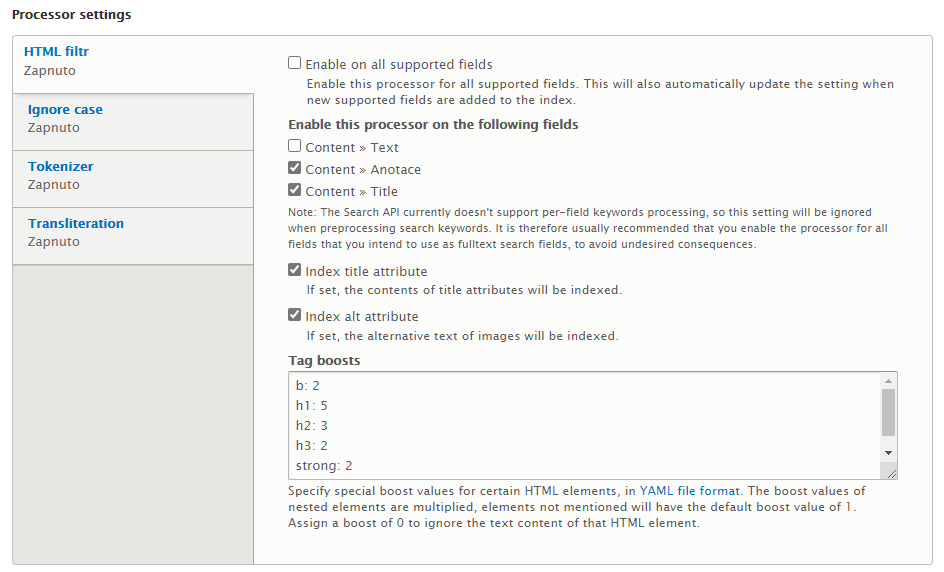
Tyto vlastnosti spolu s možností vytvářet vyhledávací stránky pomocí Views už dávají poměrně dobré možnost implementace vyhledávání, kde lze do značné míry konfigurovat způsob prohledávání, sestavování výsledků neboli vyhodnocování relevance vůči hledaným výrazům i vlastní způsob prezentace vyhledávacích formulářů a výsledků hledání.
Velkou výhodou tohoto řešení je, že není třeba instalovat žádnou další aplikaci a využívá se jen Drupal a jeho moduly, nevýhody mohou být pak zejména:
- nemožnost vyhledávání podobných slov pomocí slovních kmenů (stemming)
- prohledává se jen obsah databáze, čili opět nelze prohledávat přílohy typu PDF apod.
- nemožnost precizněji definovat vyhodnocování relevance výsledků hledání
Vyhledávání pomocí Search API + Apache SOLR
Jsou-li požadovány ještě pokročilejší vlastnosti vyhledávání než nabízí kombinace modulů Search API + Database Search, bývá nejčastější volbou nasazení aplikace Apache SOLR (https://solr.apache.org).
SOLR je samostatná aplikace specializovaná na fulltextové hledání. SOLRu je třeba poskytnout data k indexaci, tj. má rozhraní, na které lze strojově zasílat data která se mají prohledávat. Takto poskytnutá data pak definovaným způsobem indexuje a ukládá do vlastních datových struktur vhodných k prohledávání. V rámci indexace v aplikaci fungují opět procesory několika typů, které ovlivňují vytváření indexu, v terminologii SOLRu jde o analyzéry, tokenizery a filtry. Tyto procesory zajišťují rozpoznávání slov, filtraci HTML značek, rozpoznávání slovních kmenů, práci s malými a velkými písmeny, s diakritikou atd.
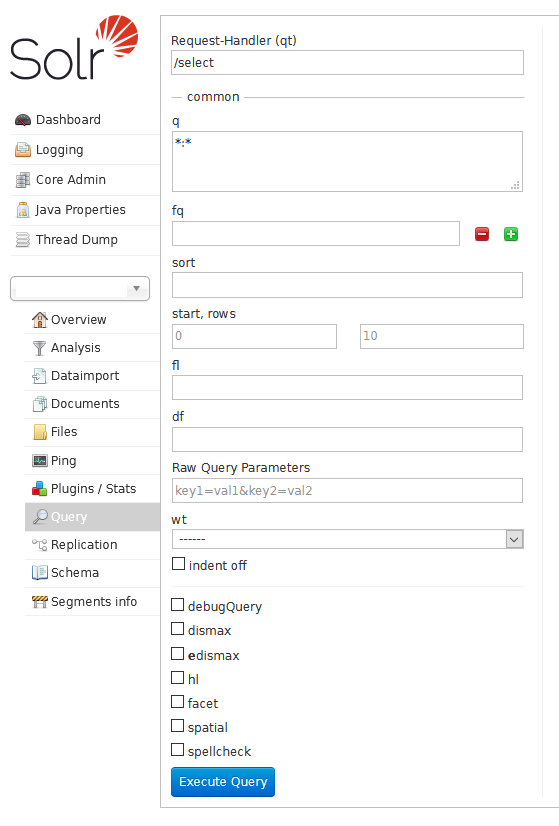
Pro hledání naopak existuje dotazovací rozhraní, na které se formou různých parametrů zasílají fulltextové dotazy a jejich vlastnosti a zpět se vrací seznam výsledků hledání v strukturované formě (XML, JSON apod.).
SOLR má i rozhraní pro extrakci textů z dokumentových formátů (PDF, MS Office formáty apod. - viz http://tika.apache.org/1.24.1/formats.html). Je tedy k dispozici i možnost prohledávání dokumentových souborů nahraných do Drupalu.
Integraci s Drupalem zajišťuje kombinace modulů Search API + Search API SOLR. Možnosti konfigurace jsou v zásadě stejné jako při využití Database Search, opět se v prostředí Drupalu definují typy obsahu které se indexují, indexovaná pole a jejich vlastnosti, procesory apod. Princip celé integrace a využití Apache SOLR je ovšem takový, že integrační modul odesílá do SOLRu data k indexaci, a naopak ve chvíli kdy se provádí nějaké hledání sestavuje dotaz na SOLR, zpět načítá výsledky hledání, tyto výsledky formátuje a prezentuje na dané vyhledávací stránce.
Ve výsledku jsou vyhledávací možnosti popsané u kombinace Search API + Database Search rozšířeny zejména o následující důležité vlastnosti:
- podpora stemmingu (i pro češtinu), tj. vyhledávání různých tvarů stejného slova podle slovních kmenů
- podpora prohledávání příloh typu PDF apod.
- možnost pokročilého ladění sestavování výsledků hledání podle relevance, tj. definovat váhy podle struktur obsahu (např. nadpis má větší váhu než vlastní text), definovat váhy podle HTML značek (H2 má větší váhu než běžný paragraf), definovat váhy podle jiných metadat (pokud mají dva dokumenty cca stejnou relevanci, větší váhu má novější dokument, dokument v nějaké kategorii apod.) atd. atd.
- Možnost vytváření slovníků synonym (a samozřejmě stopwords apod.).
Pozornost lze věnovat i způsobu prezentace hledání, je možné vytvořit např. vyhledávání s využitím tzv. facets (výsledky se rozloží např. podle nějakých kategorií a lze interaktivně omezovat zobrazování výsledku dle těchto kategorií), lze vytvářet našeptávače, využívat funkci typu „More Like This“ (vyhledávání dokumentů podobných aktuálně vybranému dokumentu) apod. Tato varianta tedy poskytuje velmi silný vyhledávací nástroj, kterým lze v českém prostředí zajistit kvalitní fulltextové hledání, a to i pro velmi rozsáhlé webové prezentace.
Vyhledávání Search API + Elasticsearch Connector
Elasticsearch je další open source vyhledávací nástroj pracující na podobných principech jako Apache SOLR, včetně využití stejného fulltextového jádra Apache Lucene.
Podobně jako pro SOLR existuje pro Elasticsearch rozšiřující modul pro Search API nazvaný Elasticsearch Connector. Jakkoliv detaily využití jsou jiné (např. konfigurace struktury indexu se provádí v případně nasazení Apache SOLR přímo v aplikaci SOLR), kdežto Elasticsearch se řídí kompletně zvnějšku přes REST API včetně definice struktur indexů apod.), principy jsou stejné a i výsledné možnosti jsou zhruba stejné. Větší rozdíl z praktického hlediska je ten, že kombinace Drupal / SOLR je uživateli využívána podstatně častěji než Drupal / Elastic Search, což znamená že při implementaci vyhledávání přes Elastic Search je větší pravděpodobnost že se narazí na problémy či chyby integračních modulů.
Závěr
Vyhledávání v rámci webové prezentace je funkce, které je vhodné při přípravě projektu věnovat dostatečnou pozornost. Vždy je důležité zvážit cíle – možnosti a kvalitu vyhledávání, a dle toho zvolit adekvátní prostředky a úsilí k jejich nasazení. Jak je v tomto článku popsáno, variant je více (a nejsou zde samozřejmě zdaleka podchyceny všechny, existuje např. možnost využít pro prohledávání webu Google Custom Search Engine apod.) a liší se jak možnostmi a kvalitou, tak potřebným úsilím, tj. náklady i mírou potřebných znalostí, takže volba adekvátní možnosti vyhledávání by měla být vždy nedílnou součástí přípravy webové prezentace.
Užitečné odkazy:
https://www.drupal.org/project/search_api
https://www.drupal.org/project/search_api_solr
https://www.drupal.org/project/elasticsearch_connector
https://solr.apache.org/guide/8_8/
https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html